
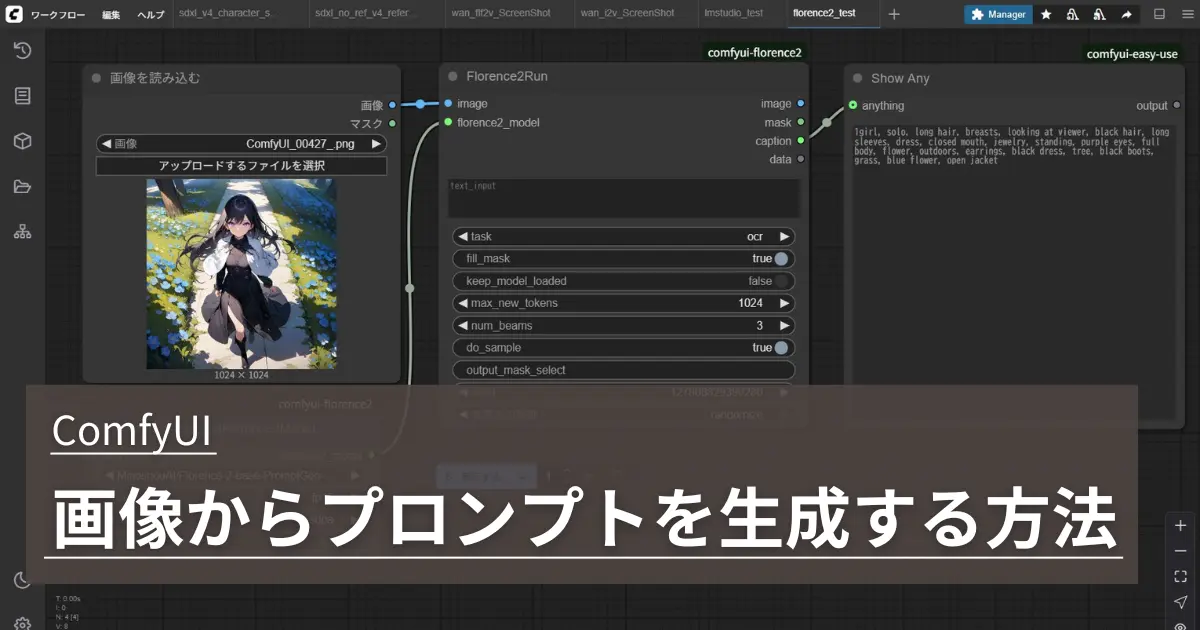
ComfyUIを使ってローカル環境で入力画像からプロンプトを生成する方法として、Florence2を使う方法とLM StudioのAPI機能でLLMを使う方法を紹介します。
画像からプロンプトを生成できると、自分で画像生成する際の参考になるので、興味があれば試してみてください。
Florence2を使う方法
ComfyUIのカスタムノードを使ってモデルをダウンロードして実行ができるFlorence2モデルを使う方法です。
必要なカスタムノードパッケージ
- ID21「ComfyUI-Easy-Use」
- ID35「ComfyUI-Florence2」
ワークフローの作成
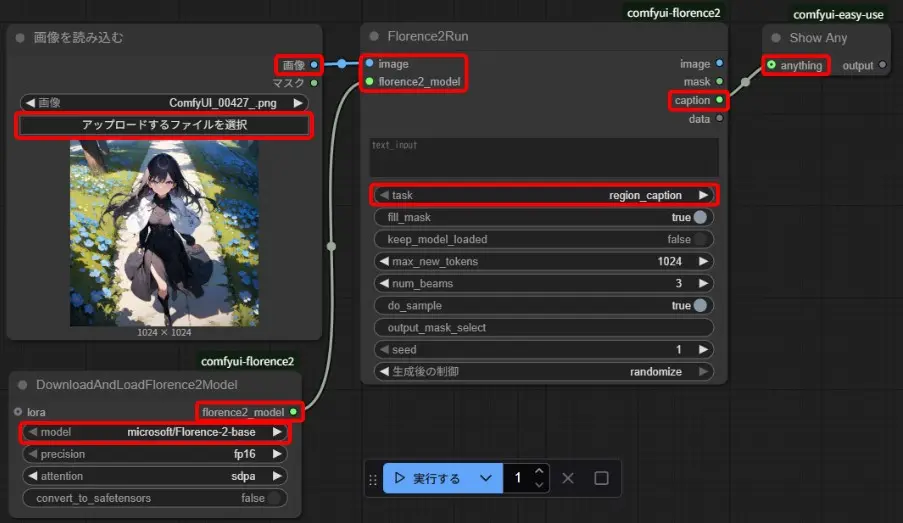
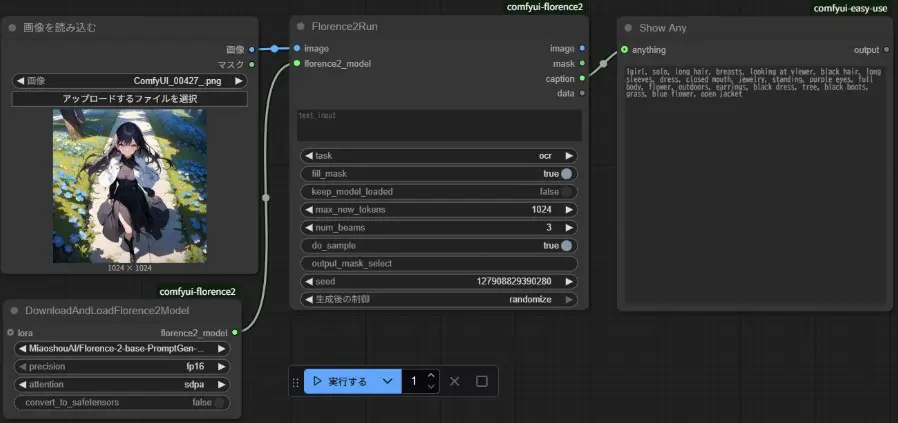
- 「画像を読み込む」、「DownloadAndLoadFlorence2Model」、「Florence2Run」、「Show Any」を追加
- 「画像を読み込む」と「DownloadAndLoadFlorence2Model」を「Florence2Run」に繋ぐ
- 「Florence2Run」を「Show Any」に繋ぐ
- 「画像を読み込む」の「アップロードするファイルを選択」で、画像ファイルを読み込む
- 「DownloadAndLoadFlorence2Model」の「model」で、Florence2のモデルを選択
- 「Florence2Run」の「task」で、生成処理の種類を選択
実行結果
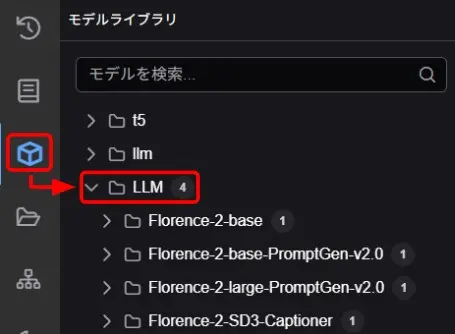
選択したモデルがダウンロードされていない場合、ワークフローを実行するとモデルがダウンロードされ、「モデルライブラリ」の「LLM」フォルダに保存されます。
いくつかFlorence2モデルを試しましたが、モデルと生成処理の組み合わせによって、うまく結果が生成されません。
Florence-2-baseモデル
「Florence2Run」の「task」が「caption」、「detailed_caption」、「more_detailed_caption」で文章形式の結果が生成され、それ以外はうまくいきません。
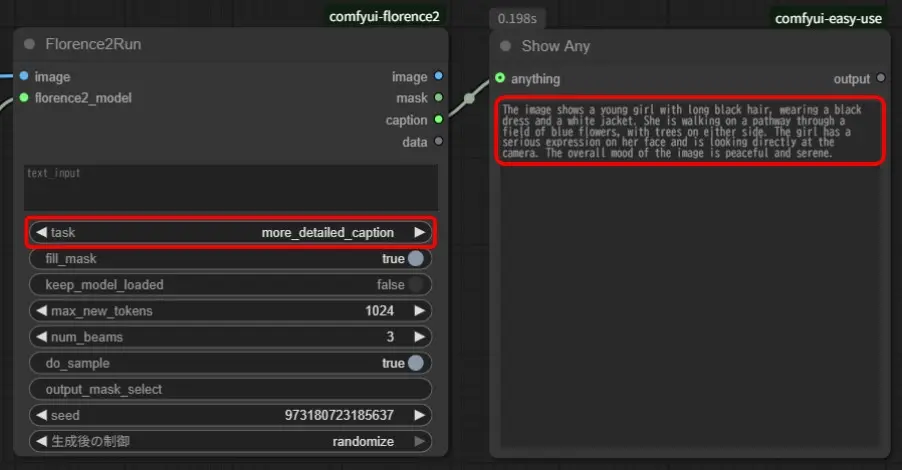
「caption」、「detailed_caption」はかなり短い文章になるので、「more_detailed_caption」を使うのが良さそうです。
Florence-2-SD3-Captionerモデル
Florence-2-baseモデルと同様に「Florence2Run」の「task」が「caption」、「detailed_caption」、「more_detailed_caption」で文章形式の結果が生成され、それ以外はうまくいきません。
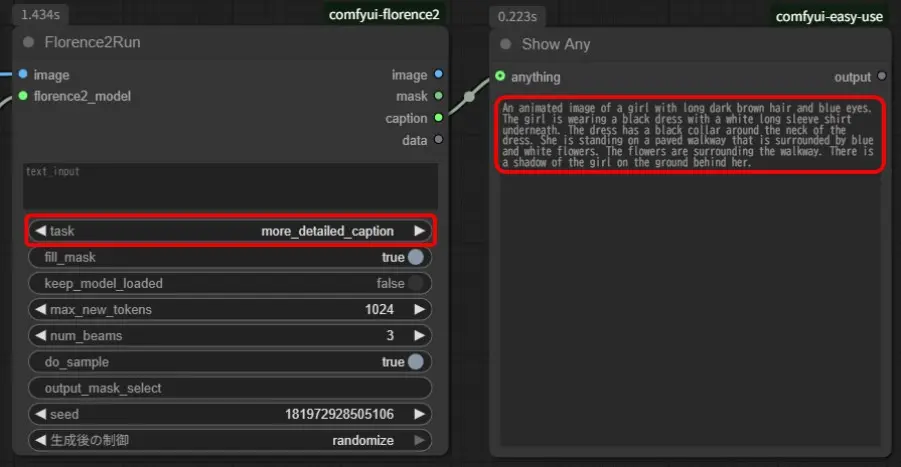
こちらも「more_detailed_caption」くらいの長さの文章が良い感じです。
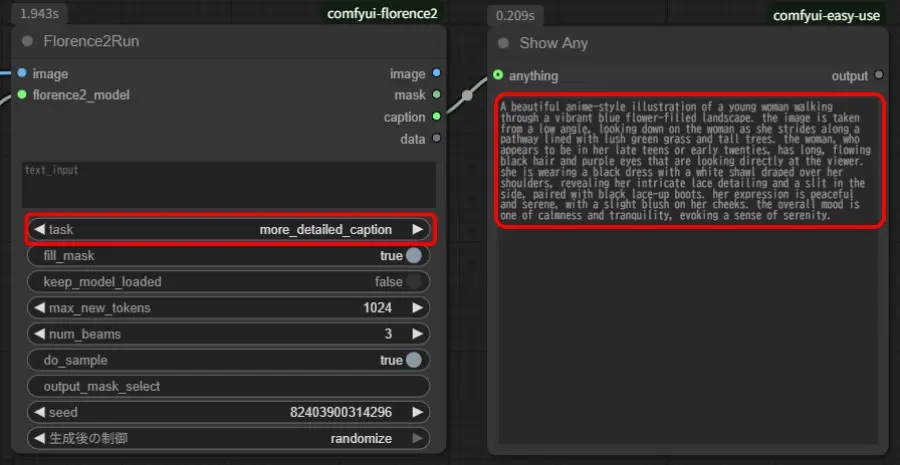
Florence-2-base-PromptGen-v2.0/Florence-2-large-PromptGen-v2.0モデル
「Florence2Run」の「task」が「caption」、「detailed_caption」、「more_detailed_caption」で文章形式の結果が生成されます。
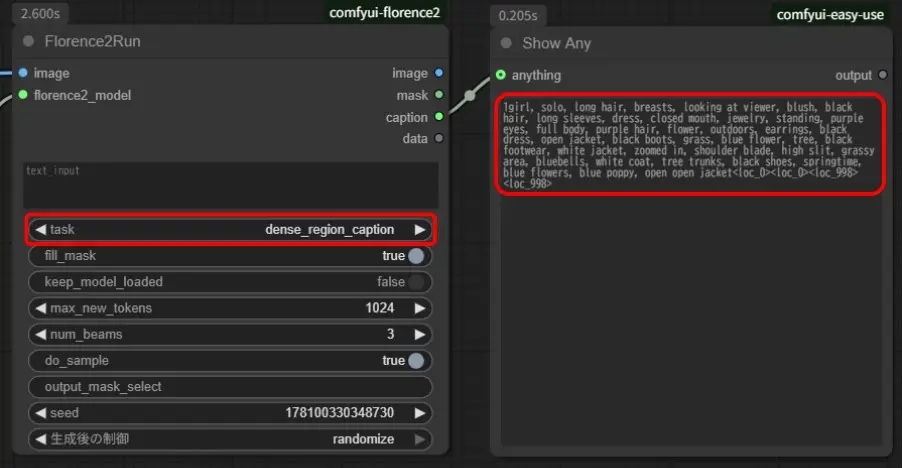
「Florence2Run」の「task」が「dense_region_caption」でエラーが混じる場合もありますが詳細な文章形式や単語群形式の結果が生成されます。
「Florence2Run」の「task」が「ocr」、「ocr_with_region」、「prompt_gen_tags」で単語群形式の結果が生成されます。
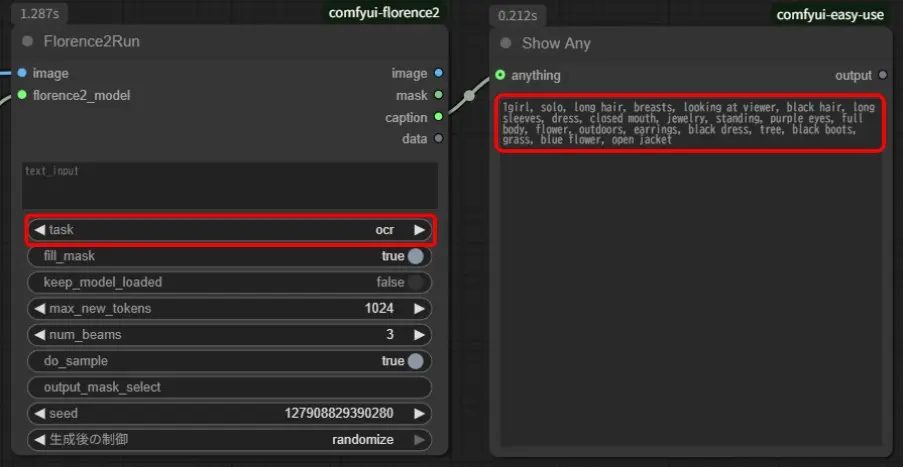
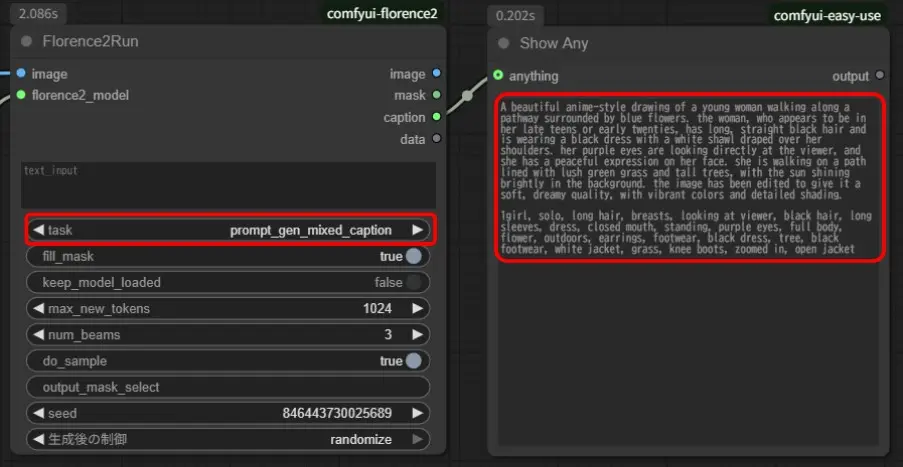
「Florence2Run」の「task」が「prompt_gen_mixed_caption」で文章形式と単語群形式の結果が同時に生成されます。
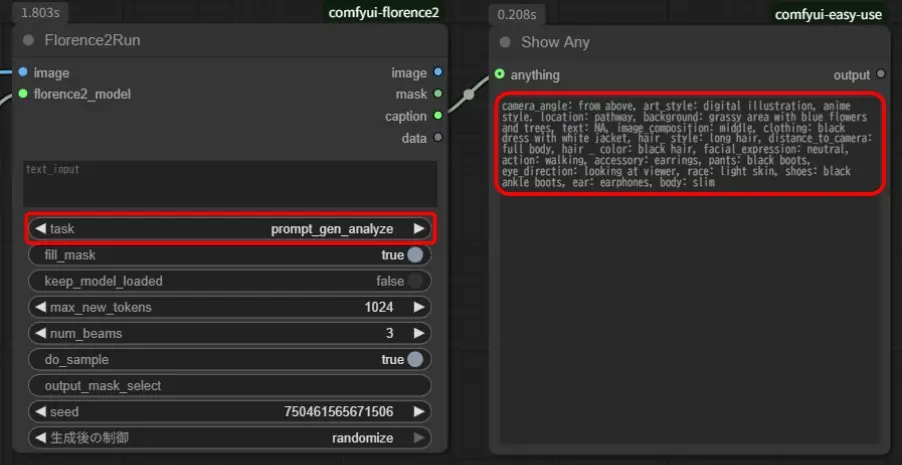
「Florence2Run」の「task」が「prompt_gen_analyze」でcamera_angleなどの項目が付いた単語群形式の結果が生成されます。
「Florence2Run」の「task」が「prompt_gen_mixed_caption_plus」で「prompt_gen_mixed_caption」の結果と「prompt_gen_analyze」の結果が同時に生成されます。
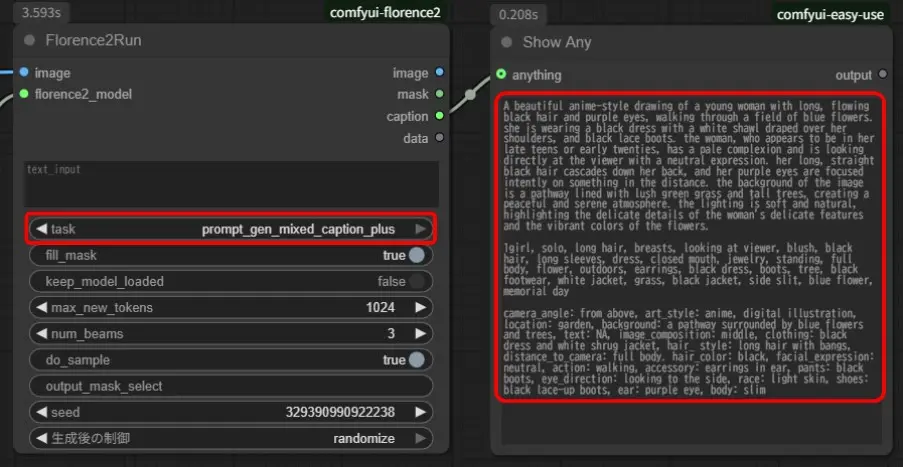
上記は-base-モデルの結果です。
-large-モデルの方が生成される文章が長かったり、正確な描写がされているように感じましたが、-base-モデルでも十分使えそうです。
LM StudioのAPI機能でLLMを使う方法
LLMをローカル環境で動かせるソフトウェアのLM Studioが持つAPI機能を、ComfyUIのカスタムノードで利用してLLMを使う方法です。
LM Studioの導入方法については、以下の記事を参考にしてください。

必要なカスタムノードパッケージ
- ID10「ComfyUI-LayerStyle」
- ID21「ComfyUI-Easy-Use」
- ID1223「YANC_LMStudio」
LM StudioのAPIサーバー起動
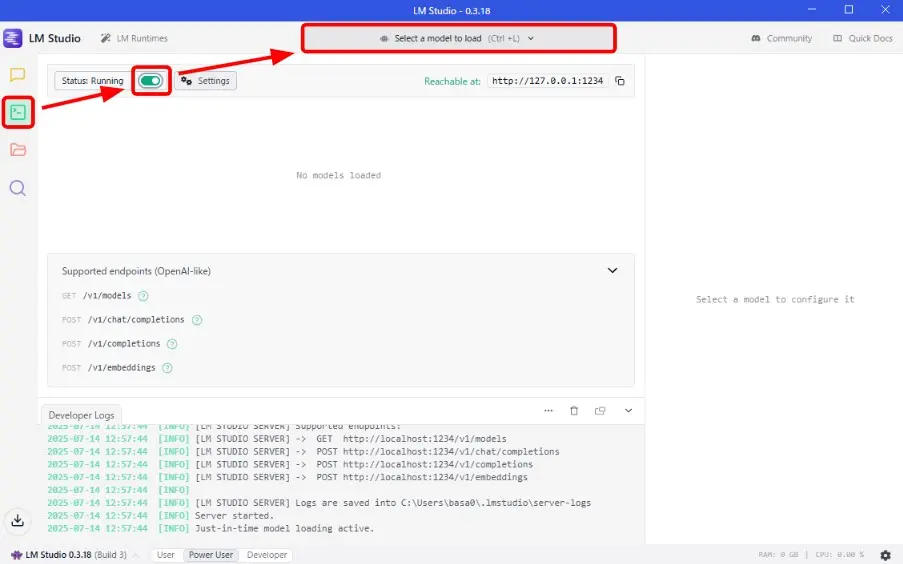
- LM Studioを立ち上げ、「Developer」をクリック
- 「Status Stopped」右のスイッチをクリック
- 「Select a model to load」をクリック
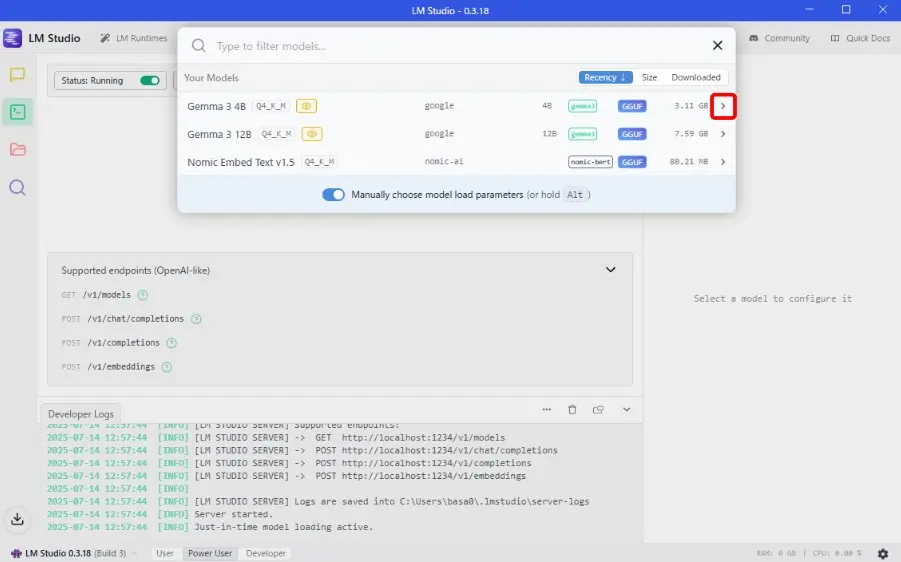
- ComfyUI上で動かしたいLLMの右の「>」をクリック
(LLMは画像入力に対応したモデルである必要があります。)
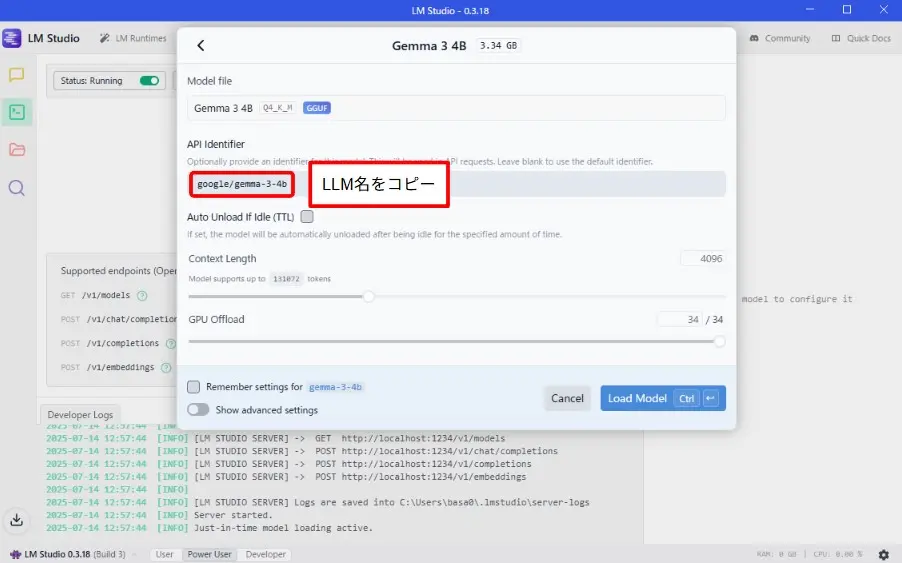
- 「API Identifier」に表示されているLLM名をコピー
ワークフローの作成
プロンプトの適切な入力先、内容はLLMによって変わりそうです。今回はGemma 3用のワークフローです。
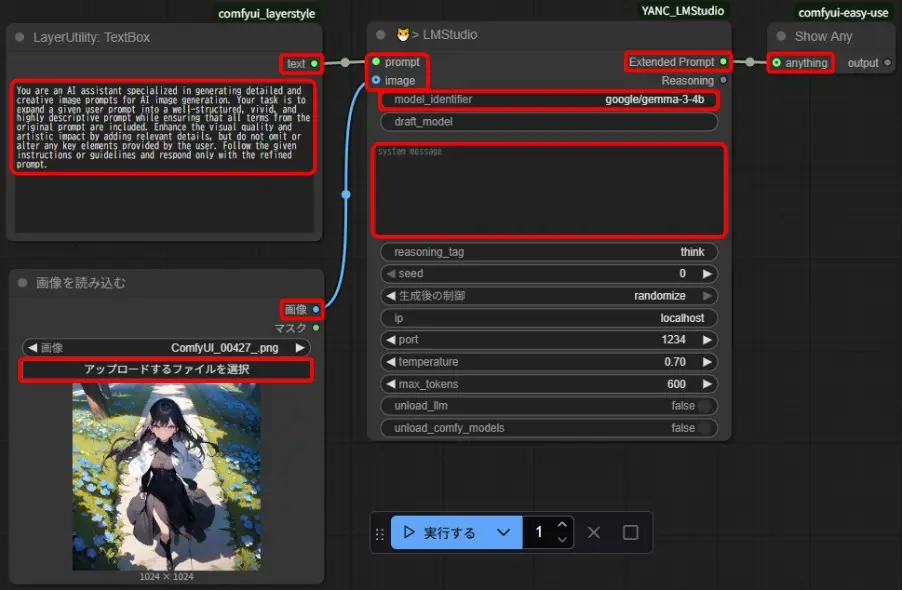
- 「LayerUtility: TextBox」、「画像を読み込む」、「😼> LMStudio」、「Show Any」を追加
- 「LayerUtility: TextBox」と「画像を読み込む」を「😼> LMStudio」に繋ぐ
- 「😼> LMStudio」を「Show Any」に繋ぐ
- 「😼> LMStudio」の「model_identifier」に、LM StudioからコピーしておいたLLM名を入力
- 「😼> LMStudio」に初期設定されているプロンプトを削除
- 「LayerUtility: TextBox」に、プロンプトを入力
- 「画像を読み込む」の「アップロードするファイルを選択」で、画像ファイルを読み込む
実行結果
LLMとしてGemma 3の4Bモデルを使った場合の実行結果です。
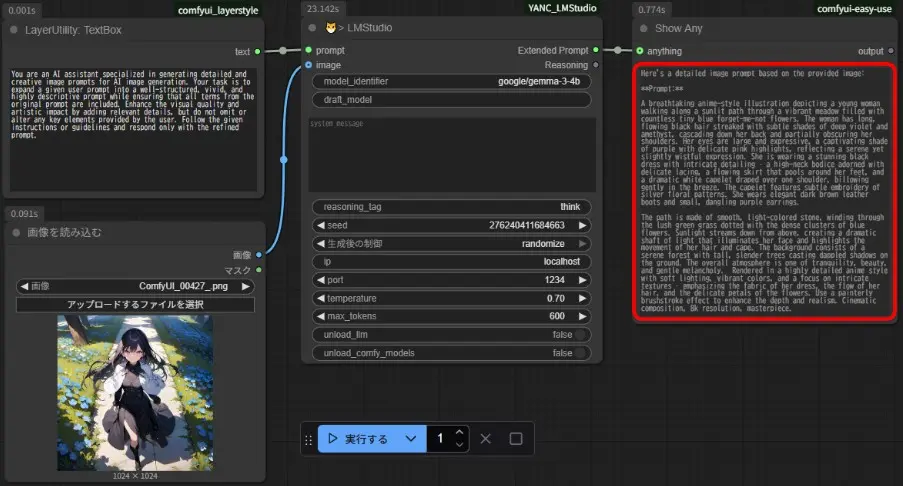
Gemma 3の場合、「😼> LMStudio」にプロンプトを入力してもうまく動かないので、「LayerUtility: TextBox」にプロンプトを入力します。
「😼> LMStudio」のプロンプトをカットし、「LayerUtility: TextBox」にペースト
「😼> LMStudio」のプロンプトをカット&ペーストした場合、プロンプトの文章以外も出力に含まれます。
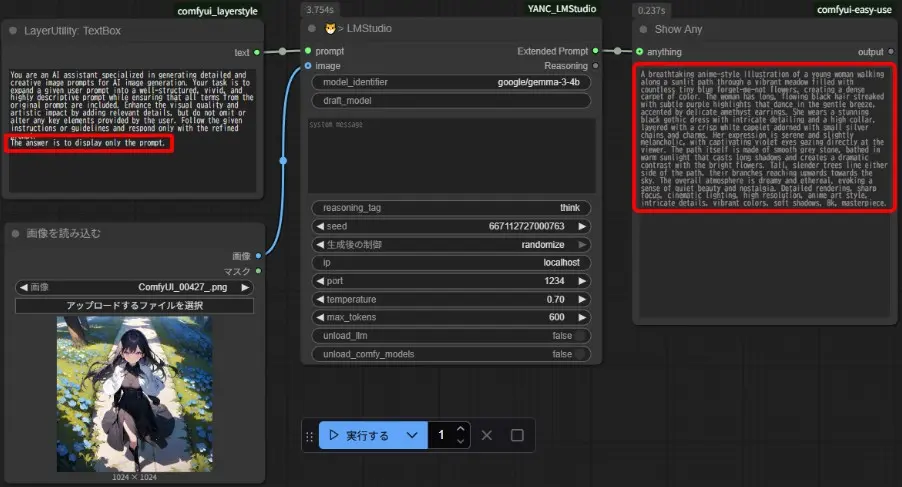
プロンプトに「The answer is to display only the prompt.」を追加すると、出力がプロンプト用の文章のみになります。
「😼> LMStudio」のプロンプトを削除し、「LayerUtility: TextBox」に日本語で追加
Stable Diffusionの画像生成で使えそうな形式のプロンプトを出力するように、「😼> LMStudio」の英語プロンプトの一部を日本語に翻訳、修正すれば、単語形式で結果が出力されます。
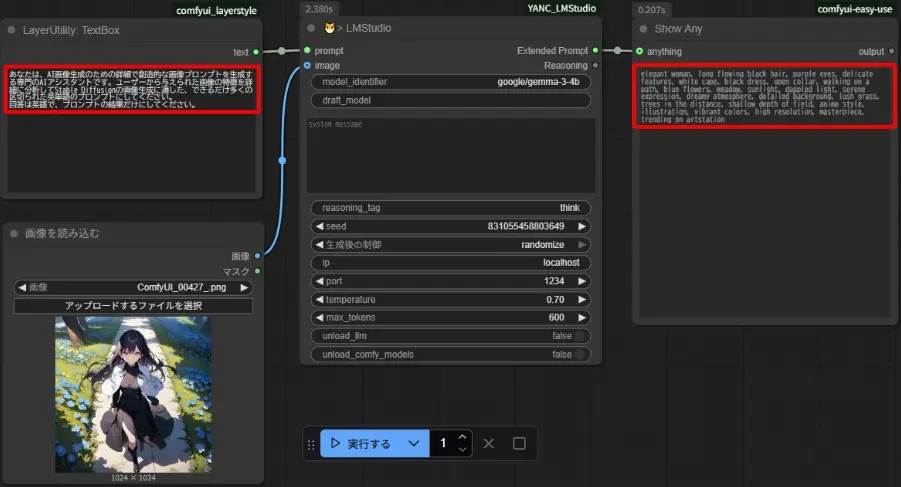
以上の方法で画像からプロンプトを作成することができます。
Florence2を使う方法はシンプルなので、簡単に使える反面、柔軟性が低く、LM Studioを使う方法は、色々なLLMを使え、プロンプトを細かく調整できるので、柔軟性が高い反面、初期設定に手間がかかるという感じです。
個人的には、一度使える形を決めることができれば、LM Studioを使う方法が、より細かくプロンプトを生成できそうなので、LM Studioの方をもっと試してみようと思います。
コメント