
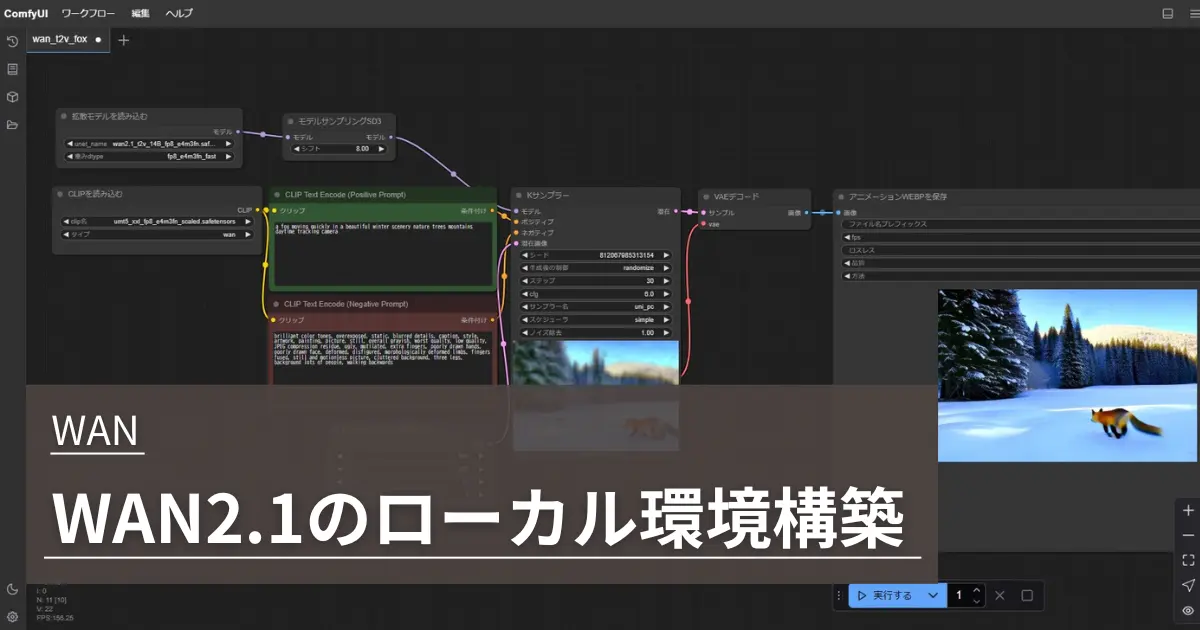
ComfyUIを使ってWAN2.1を動かすことで、動画生成できるローカル環境を構築します。
メインRAM16GB、VRAM16GBの環境でテキストからの生成と、画像からの生成ができたので、興味があれば試してみてください。

ComfyUIの導入については、以下の記事を参考にしてください。
ComfyUIのgithubにある「Examples」から「WAN」のページに紹介されている方法で、動画を生成できるようにします。
まずは、テキストから動画を生成する場合です。
WAN2.1には、いくつかモデルがありますが、ここではパラメータ数14Bの中で最も負荷が小さいモデルを試します。
テキストからの動画生成
ファイルのダウンロード
テキストから動画を生成するために、4つのファイルをダウンロードして、フォルダに保存する必要があります。
ダウンロードサイトへのアクセス

- ComfyUIのWANサンプルページにアクセス
テキストエンコーダーのダウンロード
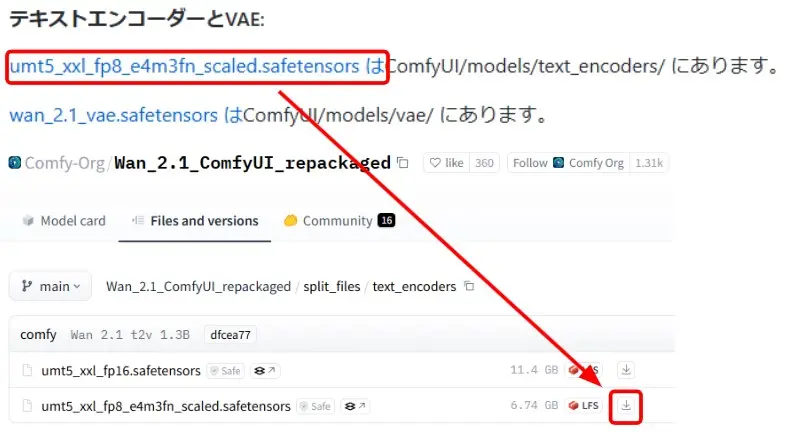
- テキストエンコーダーのリンクをクリック
- 「umt5_xxl_fp8_e4m3fn_scaled.safetensors」をダウンロード

- ダウンロードしたファイルを「ComfyUI/models/text_encoders」フォルダに移動
VAEのダウンロード
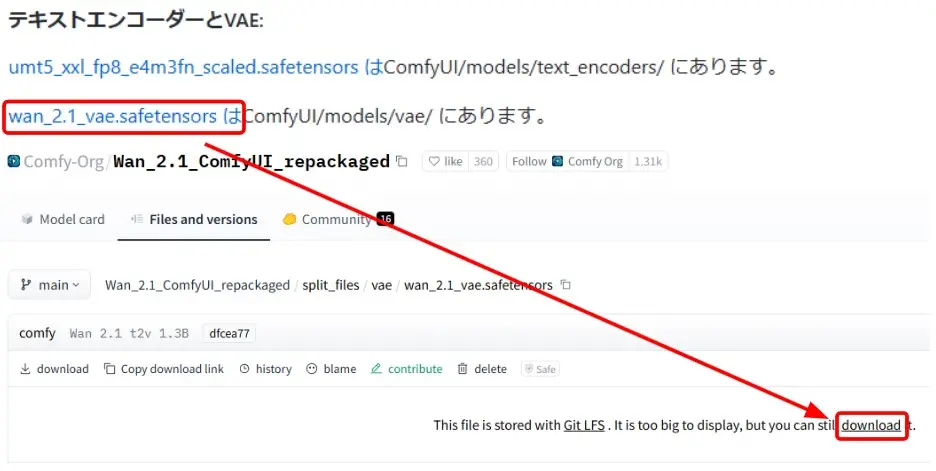
- VAEのリンクをクリック
- 「download」をクリックしてダウンロード

- ダウンロードしたファイルを「ComfyUI/models/vae」フォルダに移動
拡散モデルのダウンロード
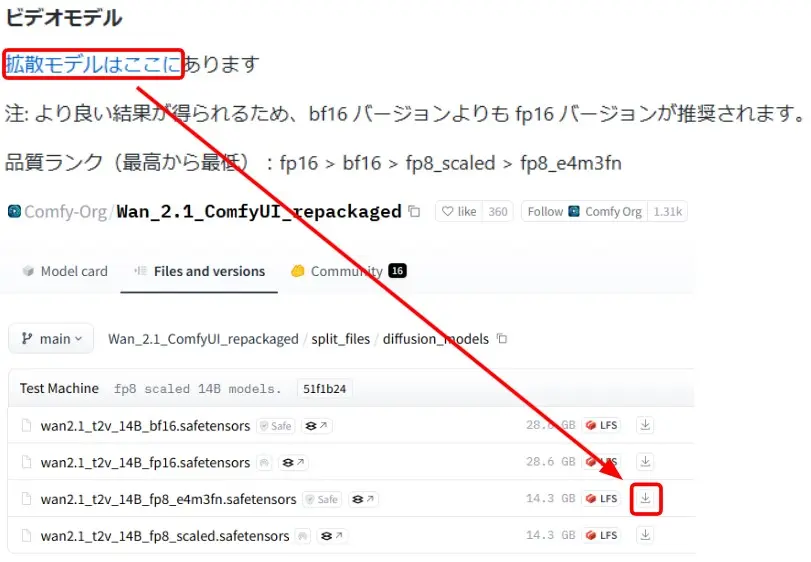
- 拡散モデルのリンクをクリック
- 「wan2.1_t2v_14B_e4m3fn.safetensors」をダウンロード

- ダウンロードしたファイルを「ComfyUI/models/diffusion_models」フォルダに移動
ワークフローのダウンロード
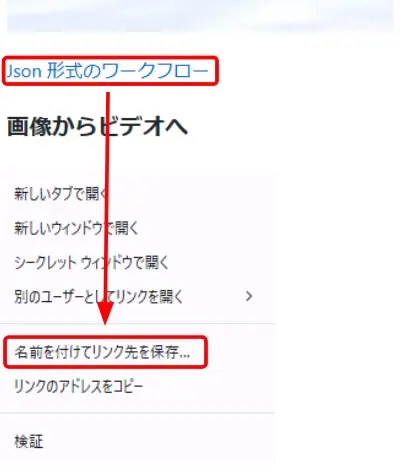
- 狐が雪の中を走っている動画の下のリンクを右クリック
- 「名前を付けてリンク先を保存」でファイルをダウンロード

- ダウンロードしたファイルを任意のフォルダ(ここでは「ComfyUI/user/default/workflows」)に移動
動画の生成
ダウンロードしたファイルを使って、ComfyUIで動画を生成します。
生成処理の実行
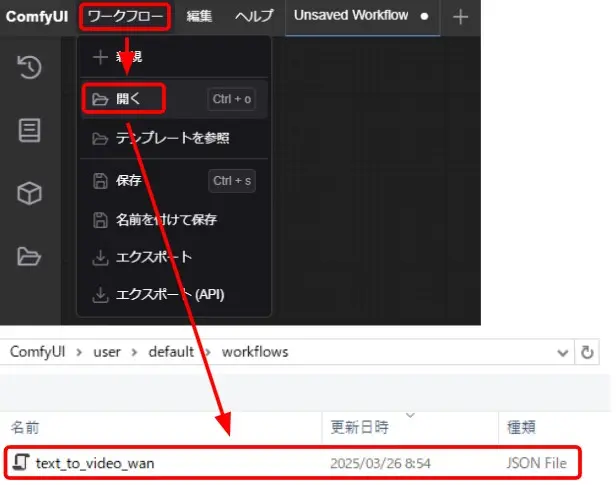
- ComfyUIを起動し、「ワークフロー」の「開く」から、ダウンロードしたワークフローファイルを選択
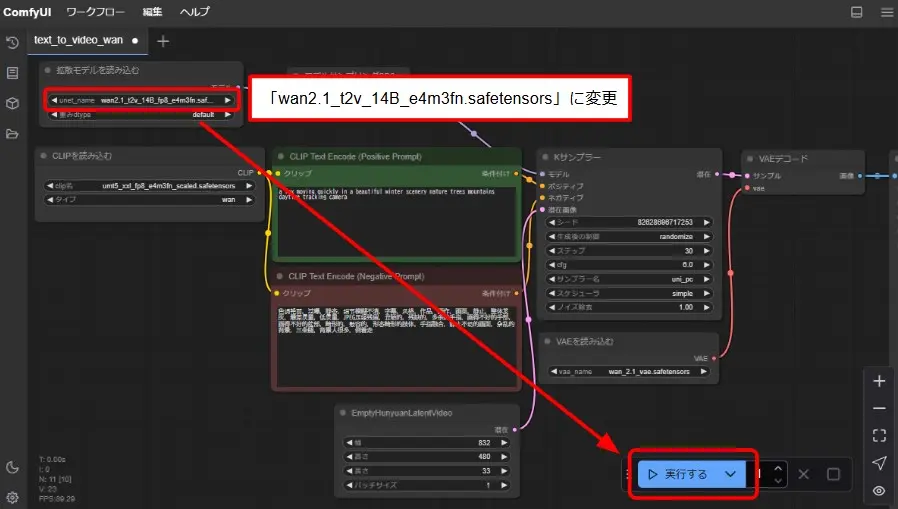
- 「拡散モデルを読み込む」で「unet_name」を「wan2.1_t2v_14B_e4m3fn.safetensors」に変更
- 「実行する」をクリックして動画生成処理を開始
処理結果
832×480、16fps、2秒間の動画を30ステップで生成するのに1104.63sかかりました。
狐の動きの連続性はとても良いですが、生成時間が20分弱程度と非常に長いです。
処理時間の短縮
生成時間を短縮するために、「拡散モデルを読み込む」の重み「dtype」を「fp8_e4m3fn_fast」に、動画サイズを480×320で生成してみました。
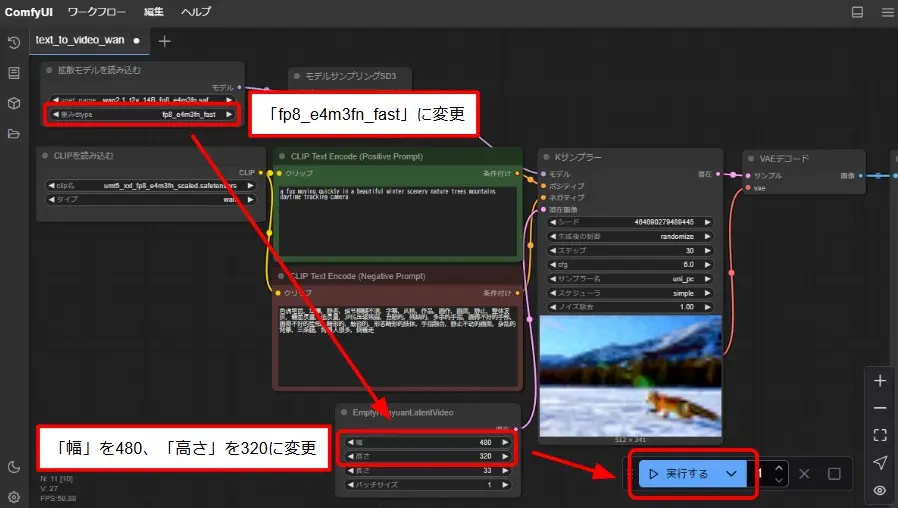
その結果、生成時間は329.50sで3分の1以下になりました。

このサイズの動画でも5分半程度かかっているので、ワークフローの改善などで、もっと高速化したいところです。
次に、画像から動画を生成する場合です。
こちらは出力画像サイズが480p(512×512)、パラメータ数14Bの中で最も負荷が小さいモデルを試します。
画像からの動画生成
ファイルのダウンロード
画像から動画を生成するためには、テキストから生成する場合と同じサイトで拡散モデル、CLIPモデル、ワークフロー、サンプル画像を新たにダウンロードする必要があります。
拡散モデルのダウンロード
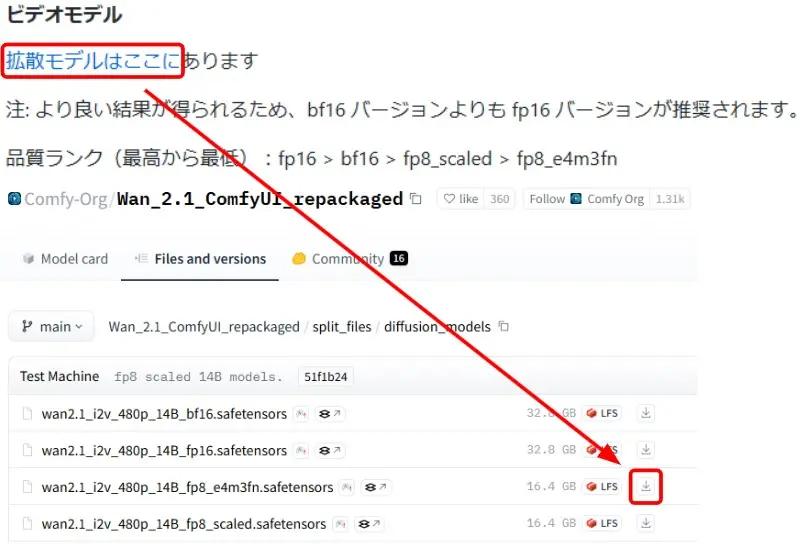
- 拡散モデルのリンクをクリック
- 「wan2.1_i2v_480p_14B_fp8_e4m3fn.safetensors」をダウンロード

- ダウンロードしたファイルを「ComfyUI/models/diffusion_models」フォルダに移動
CLIPモデルのダウンロード
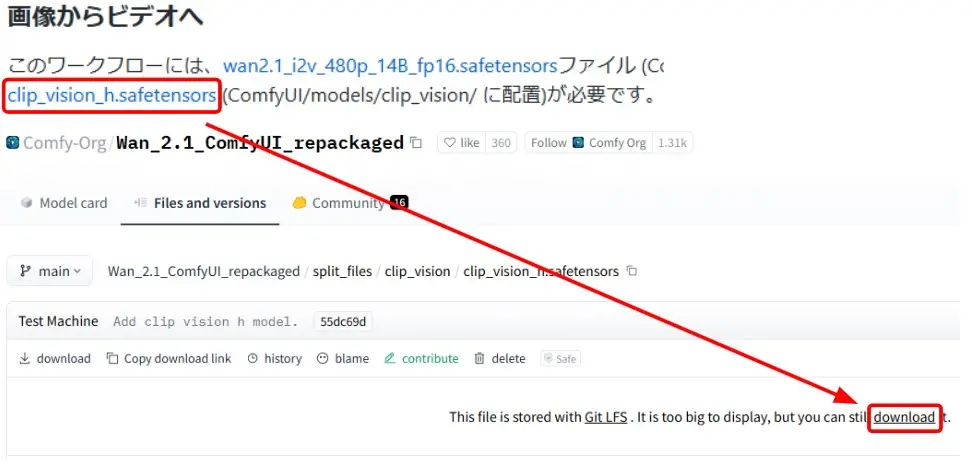
- CLIPモデルのリンクをクリック
- 「download」をクリックしてダウンロード

- ダウンロードしたファイルを「ComfyUI/models/clip_vision」フォルダに移動
ワークフローのダウンロード
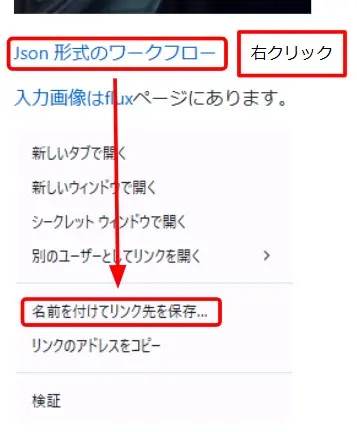
- ケモ耳メイドが回転している動画の下のリンクを右クリック
- 「名前を付けてリンク先を保存」でファイルをダウンロード

- ダウンロードしたファイルを任意のフォルダ(ここでは「ComfyUI/user/default/workflows」)に移動
サンプル画像のダウンロード
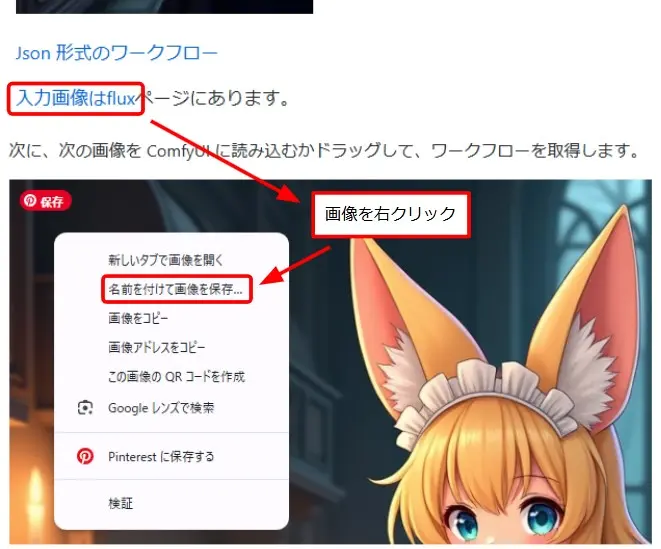
- ComfyUIのfluxサンプルページのリンクをクリック
- 一番最初の画像を右クリック
- 「名前を付けて画像を保存」でファイルをダウンロード

- ダウンロードしたファイルを任意のフォルダ(ここでは「ComfyUI/user/default/images」)に移動
動画の生成
テキストから生成する場合に使ったテキストエンコーダーとVAEに加えて、新たにダウンロードしたファイルを使って、ComfyUIで動画を生成します。
生成処理の実行
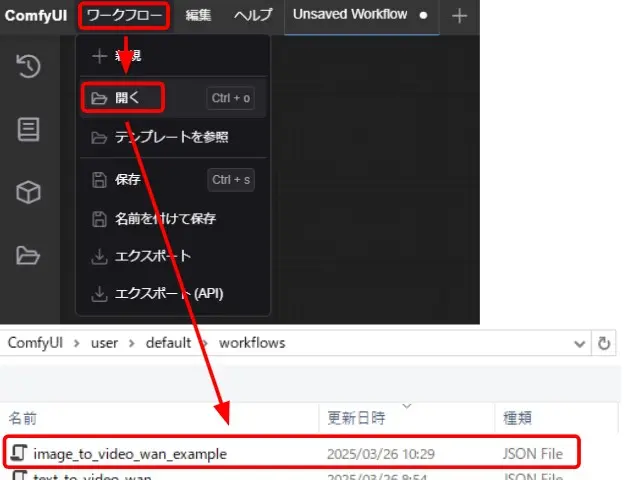
- ComfyUIを起動し、「ワークフロー」の「開く」から、ダウンロードしたワークフローファイルを選択
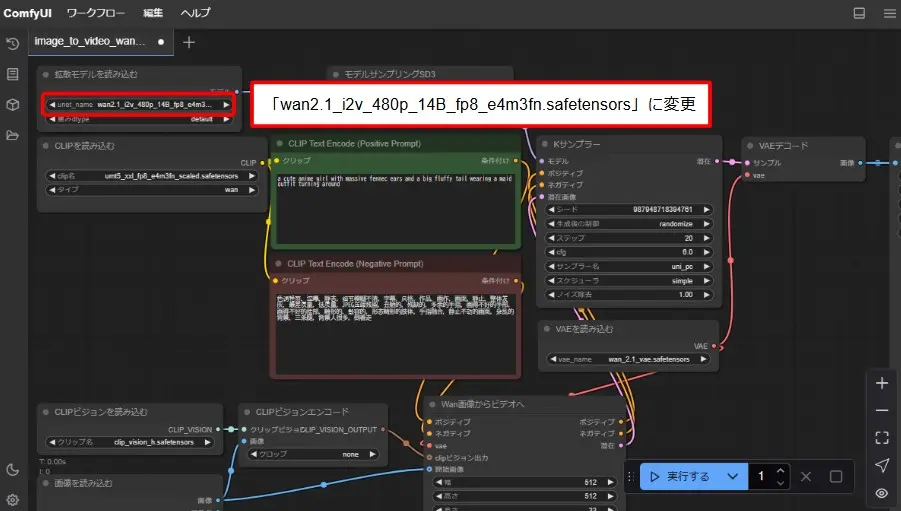
- 「拡散モデルを読み込む」の「unet_name」を「wan2.1_i2v_480p_14B_fp8_e4m3fn.safetensors」に変更
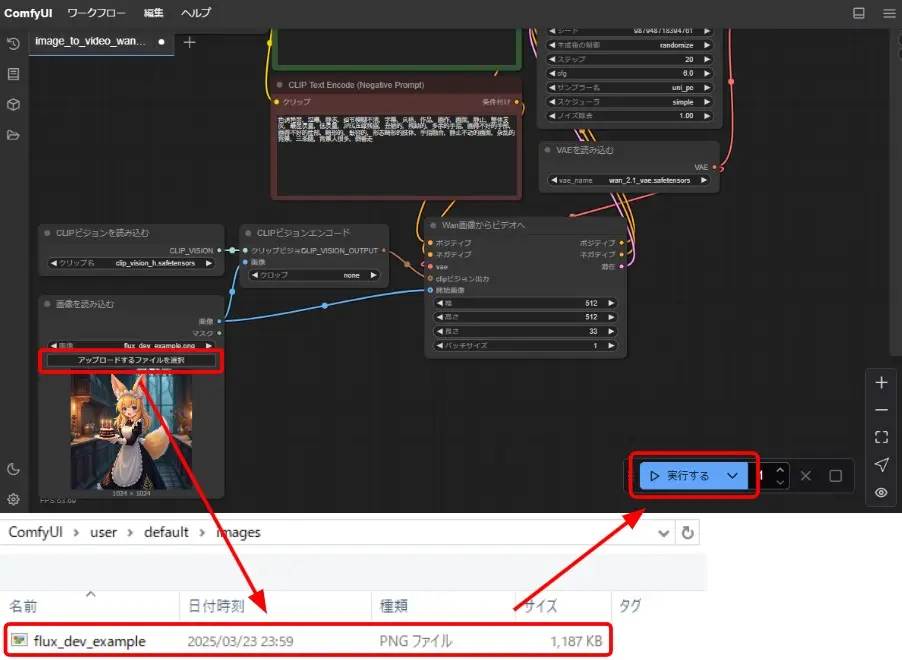
- 「画像を読み込む」の「アップロードするファイルを選択」から、ダウンロードしたサンプル画像を選択
- 「実行する」をクリックして動画生成処理を開始
処理結果
512×512、16fps、2秒間の動画を20ステップで生成するのに530.21sかかりました。
動きは機械的ですが、元の画像には無いキャラクターの背面も違和感なく生成していて驚きました。
ただ、生成時間が9分程度で、少し長いと感じました。

こちらでも「拡散モデルを読み込む」の「重みdtype」を「fp8_e4m3fn_fast」に変更してみましたが、生成時間は変わらず、元画像からの変化が大きくなってしまいました。

以上で、WAN2.1を使った動画生成のためのローカル環境が構築できました。
WAN2.1は、動作の連続性が良く、画像から生成することで結果をコントロールしやすいモデルです。
PC性能の問題もありますが、生成時間がネックなので、高速化する方法を見つけたいところです。
コメント